Implementing Real-Time Anomaly Detection with OpenObserve and Random Cut Forest

Prabhat Sharma
June 01, 2025
7 min read
Don’t forget to share!
Try OpenObserve Cloud today for more efficient and performant observability.
Get Started For Free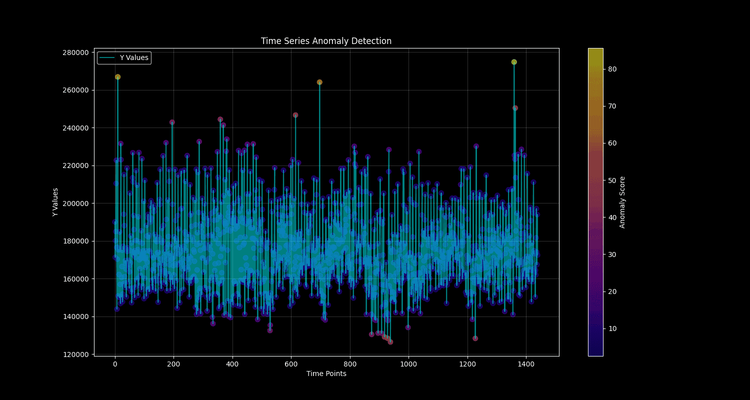
Anomaly detection in machine learning identifies unusual patterns or outliers in data, making it essential for cybersecurity, finance, IT operations, and real-time monitoring. Also known as outlier detection, machine learning anomaly detection helps teams spot deviations in time series data over hours, days, or months, preventing costly incidents.
Organizations leverage anomaly detection systems powered by advanced algorithms like Random Cut Forest or autoencoders to automate monitoring. These systems scale efficiently, reducing manual oversight and enabling real-time anomaly detection for proactive incident response.
OpenObserve is an open-source observability platform designed for real-time monitoring and analysis of logs, metrics, and traces. It provides a unified interface for streamlined application debugging, root cause analysis, and real-time anomaly detection using OpenObserve. Its scalability makes it ideal for modern cloud and hybrid environments.
Teams often use anomaly detection integrated into OpenObserve to build proactive alerts or employ machine learning models for advanced anomaly detection algorithms.
Time series anomaly detection analyzes logs, metrics, or streaming data to identify deviations from expected patterns. Common workflows include:
Algorithms like Random Cut Forest, Isolation Forest, and deep learning autoencoders excel in detecting anomalies in high-dimensional or complex time series data.
Q: What is time series anomaly detection?
A: It’s the process of using algorithms to detect unusual patterns in time-based data, ideal for monitoring and security applications.
Random Cut Forest (RCF) is an unsupervised anomaly detection algorithm optimized for real-time anomaly detection in time series data and streaming environments. It requires no labeled data and handles high-dimensional datasets, making it perfect for anomaly detection for time series data.
Advantages of Random Cut Forest:
| Algorithm | Real-Time | No Labels Needed | High-Dimensional | Memory Efficient |
|---|---|---|---|---|
| Random Cut Forest | ✅ | ✅ | ✅ | ✅ |
| Isolation Forest | ❌ | ✅ | ✅ | ❌ |
| LSTM Autoencoder | ❌ | ✅ | ✅ | ❌ |
| Statistical Methods | ✅ | ✅ | ❌ | ✅ |
| SVM | ❌ | ❌ | ✅ | ❌ |
RCF adapts to concept drift, making it ideal for Random Cut Forest for time series data where normal behavior evolves.
Ideal for:
Avoid for:
Follow these steps to implement a production-ready real-time anomaly detection system using OpenObserve and Random Cut Forest. Source code is available at GitHub: OpenObserve Anomaly Detector.
Extract numeric features (hour, minute, log volume) for anomaly detection machine learning models:
SELECT
date_part('hour', to_timestamp(_timestamp / 1000000)) AS hour,
date_part('minute', to_timestamp(_timestamp / 1000000)) AS minute,
COUNT(*) AS y
FROM "default"
GROUP BY hour, minute
ORDER BY hour, minute
LIMIT 2000
Tip: Convert categorical features to numeric for compatibility with Random Cut Forest for time series data.
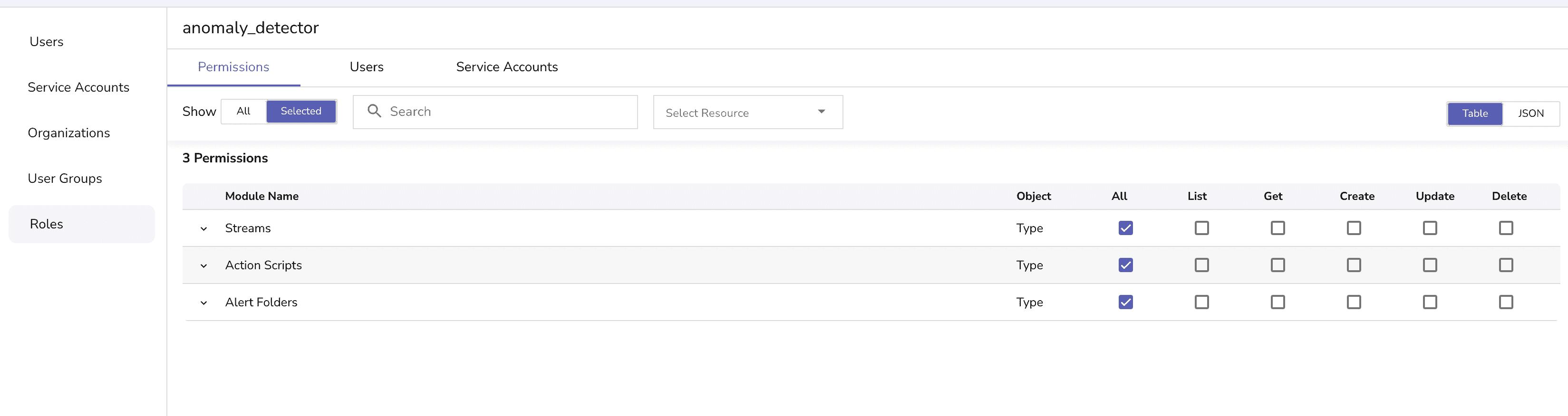
anomaly_detector_serviceaccount@openobserve.ai)anomaly_detector) with Stream, Action Scripts, and Alert Folder permissions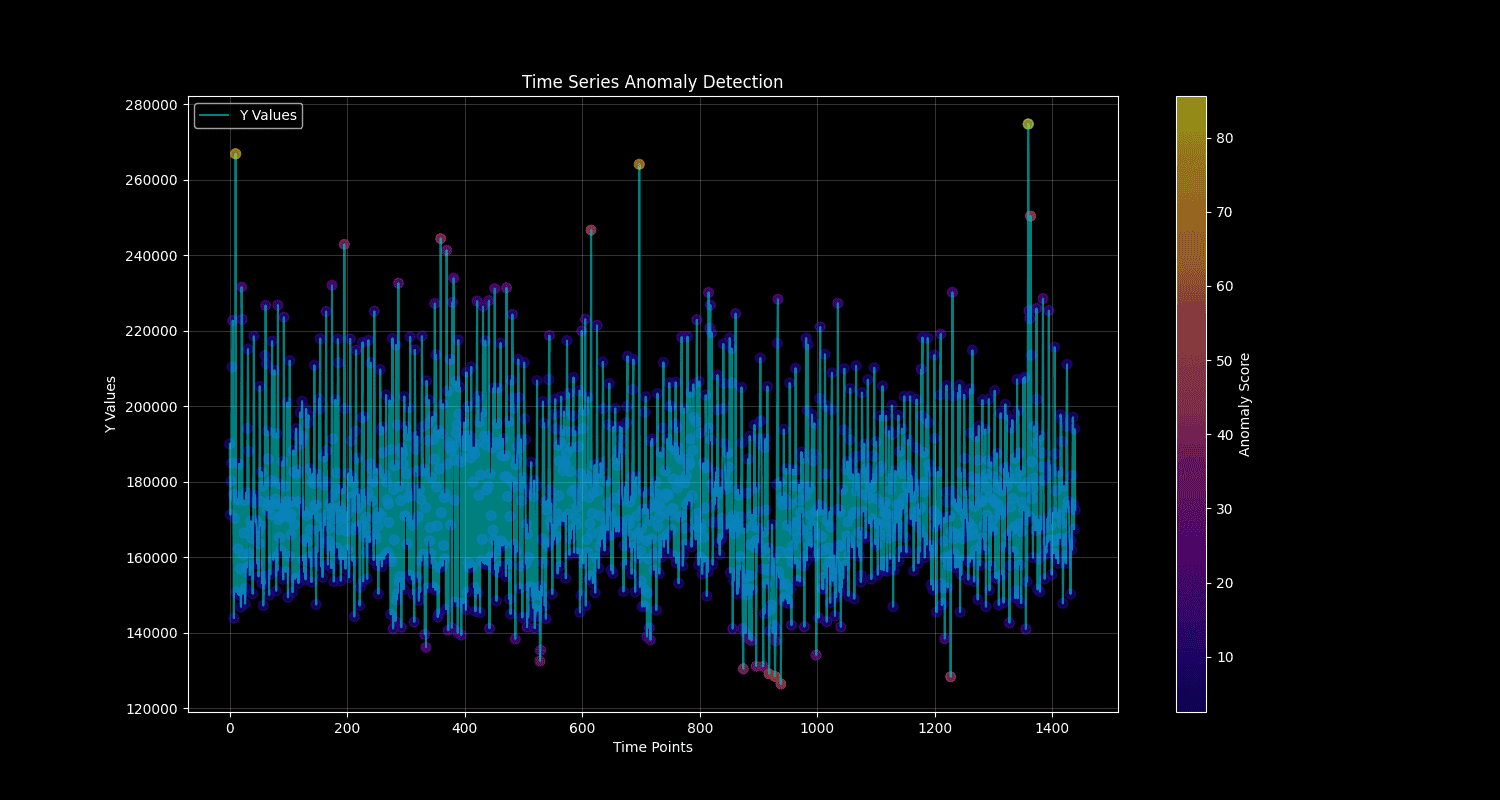 !
!
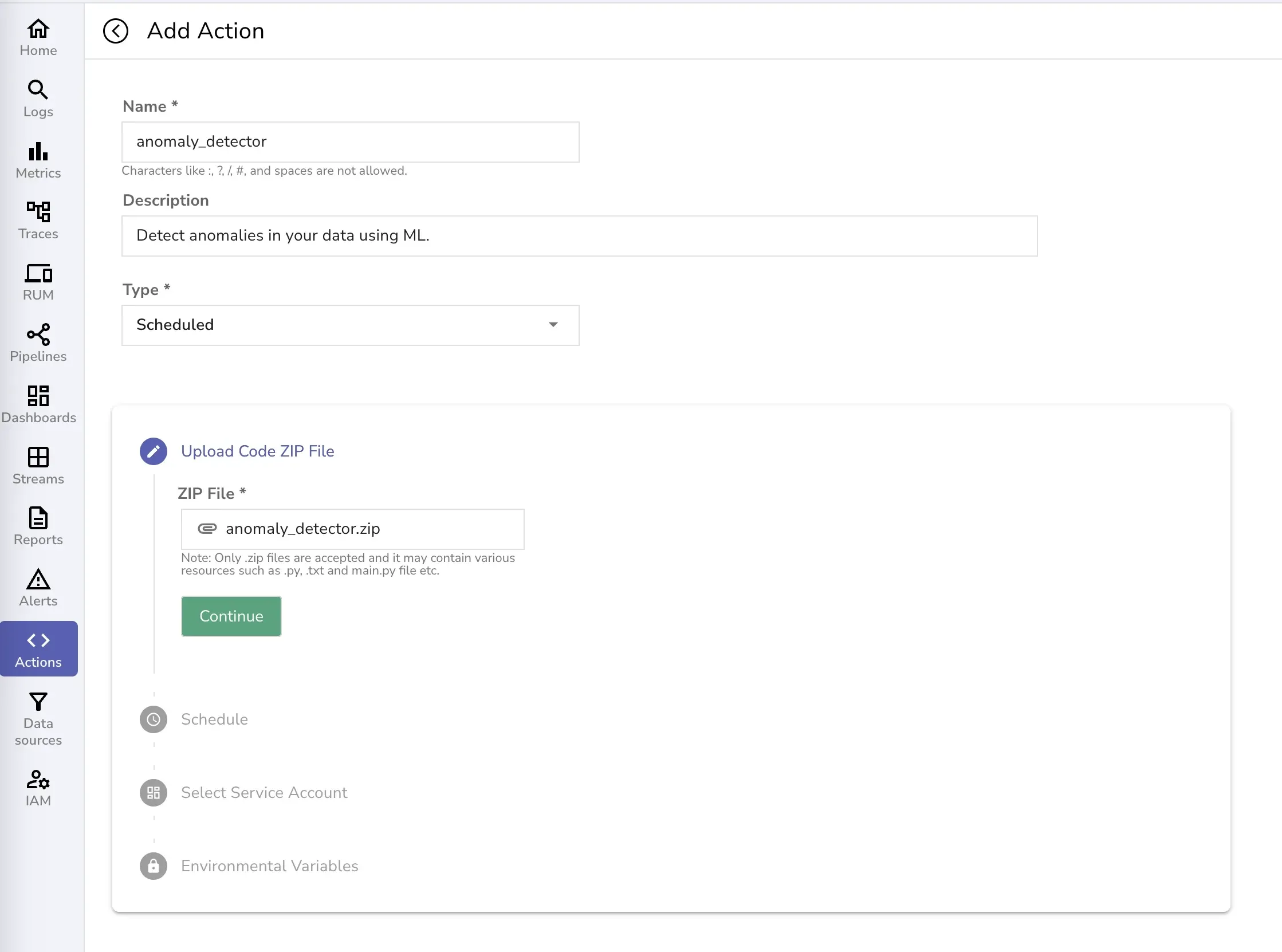
Configure credentials in a .env file for secure real-time anomaly detection using OpenObserve:
ORIGIN_CLUSTER_URL=https://your-cluster.openobserve.ai
ORIGIN_CLUSTER_TOKEN=your_base64_encoded_service_account_token
OPENOBSERVE_ORG=your_organization_name
Best Practice: Add .env to .gitignore and rotate tokens regularly for security.
Train a robust machine learning anomaly detection model with these steps:
Threshold Tip: Start at 98th percentile to balance sensitivity and reduce false positives.
Deploy the model using deploy.py and pack.sh for scheduled actions in OpenObserve. Monitor streaming data every minute, flagging anomalies in a dedicated log stream.
Post-deployment, visualize anomalies in time series data:
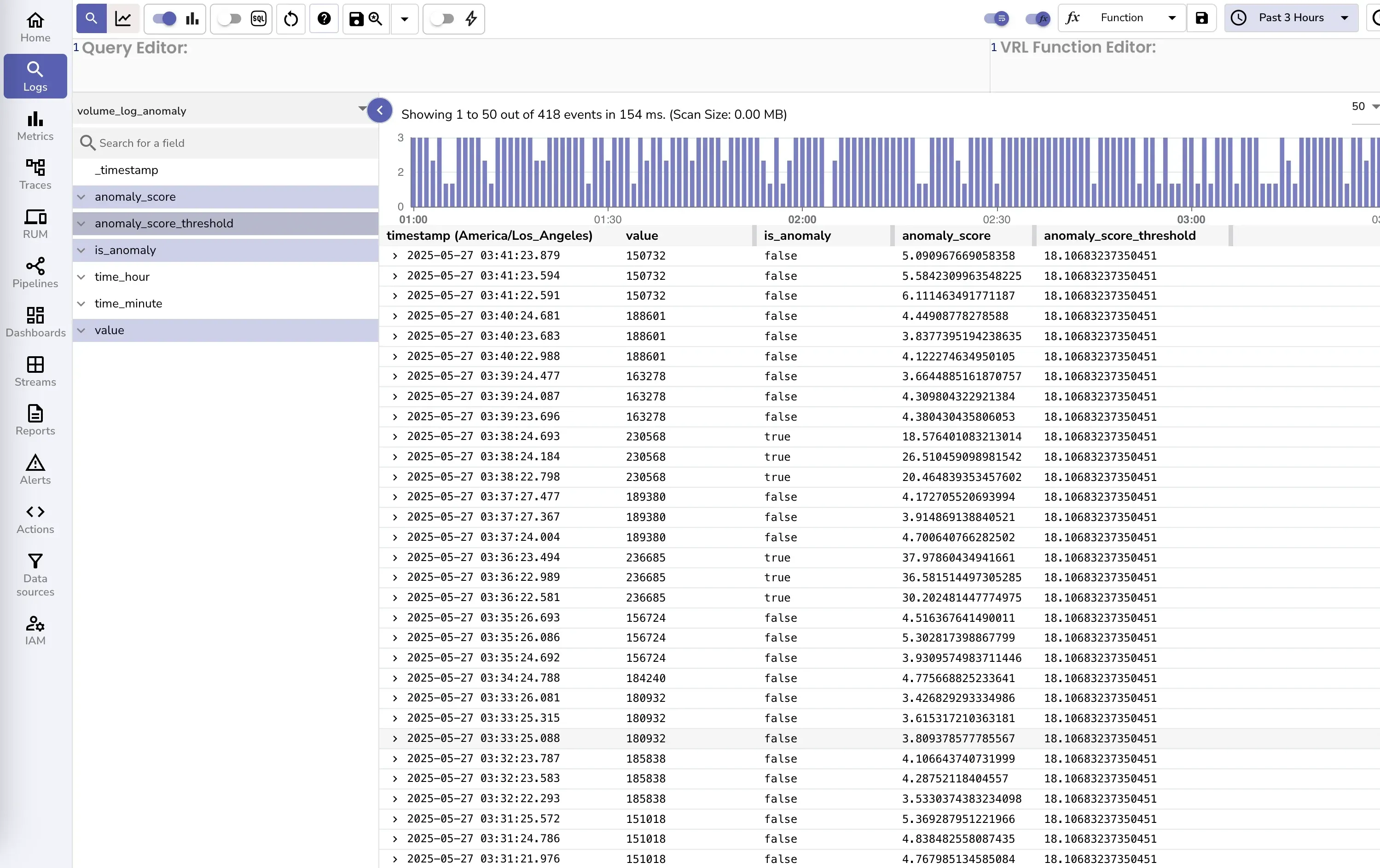
Values exceeding the threshold (~230,000 events/minute) are flagged (is_anomaly=true) and trigger real-time anomaly detection alerts.
Address common anomaly detection challenges in time series:
Tip: Regularly retrain models to adapt to concept drift for cost-effective anomaly detection solutions.
Implementing real-time anomaly detection with OpenObserve and Random Cut Forest offers scalable, intelligent monitoring for time series data. This approach ensures flexibility, actionable alerts, and minimal manual tuning. Start with our Random Cut Forest implementation guide, monitor performance, and refine thresholds for optimal results in your observability stack.
Q1: What is real-time anomaly detection in machine learning?
A: It’s the use of algorithms like Random Cut Forest to detect outliers in streaming or time series data instantly, ideal for monitoring and security.
Q2: How does time series anomaly detection work?
A: It models normal trends in time-based data, flagging deviations using statistical or machine learning methods like Random Cut Forest for time series data.
Q3: Can I implement anomaly detection in Python with OpenObserve?
A: Yes, Python libraries (e.g., scikit-learn, PyOD) integrate with OpenObserve for custom real-time anomaly detection using OpenObserve.
Q4: Is Random Cut Forest better than statistical methods?
A: RCF excels in real-time anomaly detection for high-dimensional, streaming data, offering greater flexibility than statistical methods.
Q5: What are common challenges in anomaly detection systems?
A: Issues like false positives or concept drift require careful threshold tuning and regular retraining for troubleshooting anomaly detection systems.
Prabhat Sharma is the founder of OpenObserve, bringing extensive expertise in cloud computing, Kubernetes, and observability. His interests also encompass machine learning, liberal arts, economics, and systems architecture. Outside of work, Prabhat enjoys spending quality time playing with his children.